排序算法
排序中相关术语解释:
稳定:如果a原本在b前面,而a=b,排序后a仍然在b前面
不稳定:如果a原本在b前面,而a=b,排序后a可能在b后面
基数排序(桶排序的扩展),从个位开始对一个数组进行排序,然后是十位、百位(十位百位没有数字就补零),因为十位的排序建立在个位排序的基础之上,百位建立在十位排序的基础之上,所以该算法排序是正确的,排序次数位数组中最大数字的位数,举例如下:
53 3 542 748 14 214
个位排序:542 53 3 14 214 748
十位排序:3 14 214 542 748 53
百位排序:3 14 53 214 542 748
查找算法
插值查找(定位mid的公式进行了优化):将二分查找中求mid的公式改为
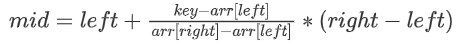
举例说明:数组arr={1,2,3,……100},假如需要查找的值为1,第一次得到的mid=0+(99-0)*(1-1)/(100-1)=0,公式将mid的求法变为计算key(key是要查找的值)与arr[left]的差距占arr[right]-arr[left]的比例乘此时的数组长度,因为数组是有序的,所以该公式可以快速的找到与key值接近的位置
该算法中需要注意:因为key参与寻找mid(自适应),所以如果key很大的话会导致算出来的mid很大直接越界,而key在arr[left]和arr[right]之间可以保证该公式算出来的值一定不越界,插值查找存在局限性,当数组中的有序元素之间存在较大差距时(或者说需要查找的数组中的元素分布不均匀时),插值查找的效率往往不如二分查找
树
二叉树
- 前序遍历:中左右;中序遍历:左中右;后序遍历:左右中(父节点先输出就是前序,父节点中间输出为中序,父节点最后输出为后序)
- 满二叉树:该二叉树的所有叶子节点(没有子节点的节点)都在最后一层,并且结点总数=$2^n$-1,n为层数
- 完全二叉树:若设二叉树的高度为h,除第h层外,其他各层(1~h-1)的节点数都达到最大个数,第h层上的节点都集中在该层最左边的若干位置上
顺序存储二叉树:存储方式是从树结构上看,从上到下从左到右将每一个节点的值存在数组中。需要实现的方法是将这样存储好的数组以树的方式来进行遍历输出
顺序存储二叉树的特点:
- 通常只考虑完全二叉树
- 第n个元素的左子节点为2*n+1(这里及下面的n表示二叉树(其实是数组)中的第几个元素,按零开始编号)
- 第n个元素的左子节点为2*n+2
- 第n个元素的父节点为(n-1)/ 2(向下取整除法)
顺序存储二叉树在堆排序中会用到,可以用数学归纳法证明上面的公式
二叉排序树:对于二叉排序树的任何一个非叶子结点,要求左子结点的值比当前结点的值小,右子结点的值比当前结点的值大。(如果有相同的值,可以将该结点放在左子结点或右子结点)
平衡二叉树首先是二叉排序树,它是在二叉排序树的基础上实现的。
平衡二叉树的特点:它是一棵空树或者它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一颗平衡二叉树,平衡二叉树的实现方法有:红黑树、AVL等。
堆:
最大堆(又叫大顶堆):堆顶是整个数组中最大的元素,且任何父节点的值都大于其子节点
最小堆(又叫小顶堆):堆顶是整个数组中最小的元素,且任何父节点的值都小于其子节点
堆(通常是顺序存储二叉树得到的)的一些操作:下面以最大堆为例
插入一个元素:每次插入都是将先将新数据放在数组最后,由于从这个新数据的父结点到根结点必然为一个有序的序列,现在的任务是将这个新数据插入到这个有序序列中——这就类似于直接插入排序中将一个数据并入到有序区间中。我们交换我们的插入元素和它的父节点,直到它的父节点比它大或者我们到达树的顶部。这就是所谓的 shift-up,每一次插入操作后都需要进行。它将一个太大或者太小的数字“浮起”到树的顶部。
1
2
3
4
5
6
7public static void shiftUp(int[] arr, int index) {
int parentIndex=(index - 1) / 2;
if (parentIndex >= 0 &&arr[index]>arr[parentIndex]){
swap(arr,index,parentIndex);
shiftUp(arr,parentIndex);
}
}删除堆顶元素:堆中每次都只能删除堆顶元素删除一个元素,由于堆的完全二叉树的特点限制,要提防出现最后一层断层,即不连续。
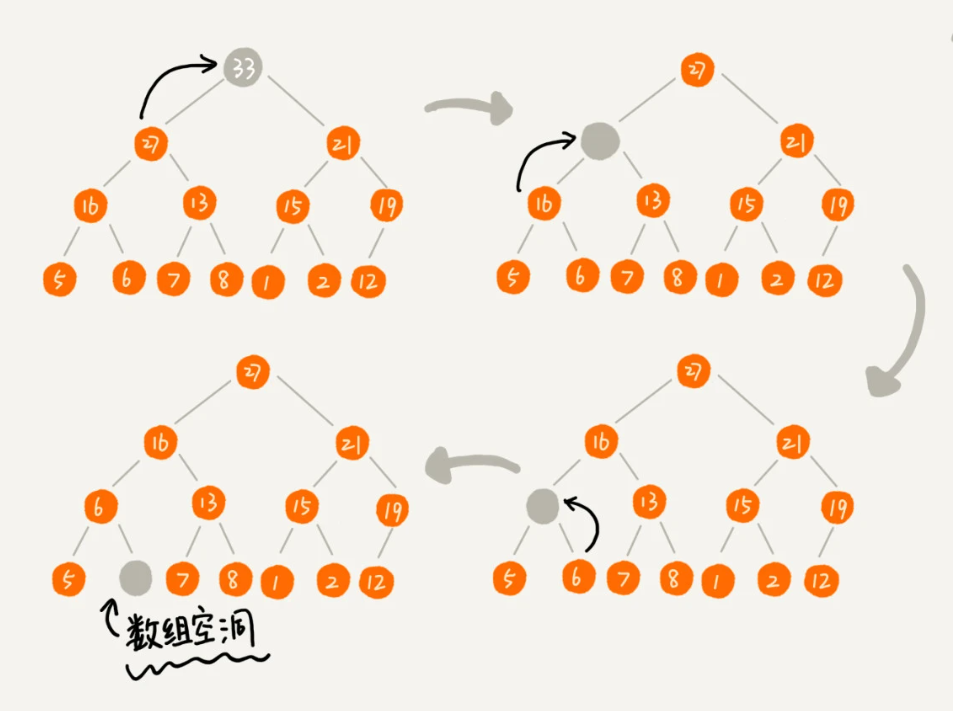
所以采用的方法是把最末的元素替换堆顶再进行堆化,这样得到的新堆肯定是符合其自身特点的。很明显,这里是从上往下的堆化过程。
删除堆顶元素的算法如下:将堆顶元素与堆的末尾的元素交换,然后删除该元素后(此时删除的是末尾一个元素),从堆的根结点调用shift-down。为了保持最大堆的堆属性,我们需要树的顶部是最大的数据。从根节点开始,找到左右子节点中小的那个,将根结点与之交换,在递归进行比较,直到该节点没有任何子节点或者它比两个子节点都要大为止
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public static void adjustHeap(int[] arr, int i, int len) {
//这个代码中我实现的是最大堆
//这个函数就是shiftDown():如果一个节点比它的子节点小(最大堆),
//那么需要将它向下移动。这个操作也称作“堆化(heapify)”。
if (2 * i + 1 >= len) {
return;
}
int left = 2 * i + 1;
int right = 2 * i + 2;
int largestIndex = i;
if (left < len && arr[left] > arr[largestIndex]) {
largestIndex = left;
}
if (right < len && arr[right] > arr[largestIndex]) {
largestIndex = right;
}
if (largestIndex != i) {
swap(arr, i, largestIndex);
adjustHeap(arr, largestIndex, len);
}
}构造最大堆:首先将每个叶子节点视为一个堆,再将每个叶子节点与其父节点一起构造成一个包含更多节点的堆。所以,在构造堆的时候,首先需要找到最后一个节点的父节点,从这个节点开始构造最大堆;直到该节点前面所有分支节点都处理完毕,这样最大堆就构造完毕了。
1
2
3
4
5
6public static void buildMaxHeap(int[] arr, int len) {
//因为顺序化二叉树是从左至右从上至下,所以最后一个叶子节点(len-1)的父节点(len-1-1)/2一定是最后一个非叶子节点
for (int i = len / 2 - 1; i >= 0; i--) {
adjustHeap(arr, i, len);
}
}
优先队列:就是堆
最大优先队列:无论入队的顺序,当前最大的元素先出列。
最小优先队列:无论入队的顺序,当前最小的元素先出列。说明:以最小优先队列为例
- 入队操作
优先队列本质上就是用二叉堆来实现的,每次插入一个数据都是插入到数据数组的最后一个位置,然后再做上浮操作,如果插入的数是数组中最大数,自然会上浮到堆顶。 - 出队操作
出队操作就是返回堆顶最小堆的数据之后用数组最后的数插入到堆顶,之后再做下沉操作。
- 入队操作
图
图的一些基本知识:
连通图:在无向图中任意两个顶点都是连通的(可以不是直接相连),则称该图为连通图。
非连通图:易知为上面定义的反面
图的深度优先遍历(Depth First Search简称DFS):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public void dfs(int i){
isVisited[i]=true;//标记为已访问
System.out.print(vertexList.get(i)+"->");
for (int j = 0; j < vertexList.size(); j++) {
// 这里的for循环就有递归回溯,从当前结点的第一个邻接结点递归遍历后,
// 会继续寻找当前结点的下一个未访问的邻接结点,如果有就再次进行递归遍历
if (edges[i][j]==1&&!isVisited[j]){
dfs(j);
}
}
}
//今后调用的是dfsTraverse,以图的所有结点作为初始结点进行遍历,除去已访问的结点
public void dfsTraverse(){
for (int i = 0; i < vertexList.size(); i++) {
if (!isVisited[i]){
dfs(i);//对未访问过的顶点调用dfs,如果是连通图,只会执行一次该语句,今后for循环的顶点都已经访问过了
}
}
}图的广度优先遍历(Broad First Search简称BFS):
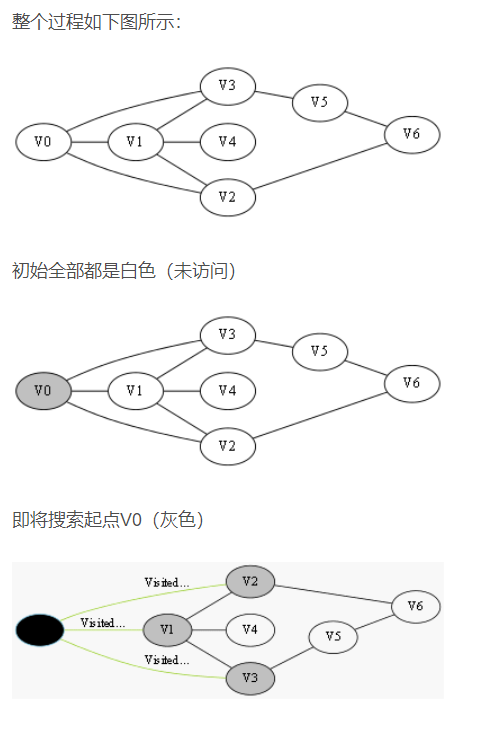
我们采用示例图来说明这个过程,在搜索的过程中,初始所有节点是白色(代表了所有点都还没开始搜索),把起点V0标志成灰色(表示即将辐射V0),下一步搜索的时候,我们把所有的灰色节点访问一次,然后将其变成黑色(表示已经被辐射过了),进而再将他们所能到达的节点标志成灰色(因为那些节点是下一步搜索的目标点了),但是这里有个判断,就像刚刚的例子,当访问到V1节点的时候,它的下一个节点应该是V0和V4,但是V0已经在前面被染成黑色了,所以不会将它染灰色。这样持续下去,直到目标节点V6被染灰色,说明了下一步就到终点了,没必要再搜索(染色)其他节点了,此时可以结束搜索了,整个搜索就结束了。然后根据搜索过程,反过来把最短路径找出来,下图中把最终路径上的节点标志成绿色。

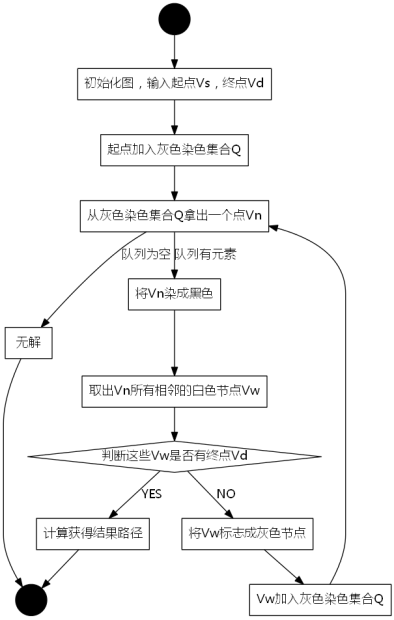
为了便于进行搜索,要设置一个表存储所有的结点。由于在广度优先搜索算法中,要满足先生成的结点先扩展的原则,所以存储结点的表一般采用队列这种数据结构。
在编写程序时,可用数组q模拟队列。front和rear分别表示队头指针和队尾指针,初始时front=rear=0。
元素x入队操作为 q[rear++]=x;
元素x出队操作为 x =q[front++];
广度优先搜索算法的搜索步骤一般是:
(1)从队列头取出一个结点,检查它按照扩展规则是否能够扩展,如果能则产生一个新结点。
(2)检查新生成的结点,看它是否已在队列中存在,如果新结点已经在队列中出现过,就放弃这个结点,然后回到第(1)步。否则,如果新结点未曾在队列中出现过,则将它加入到队列尾。
(3)检查新结点是否目标结点。如果新结点是目标结点,则搜索成功,程序结束;若新结点不是目标结点,则回到第(1)步,再从队列头取出结点进行扩展。
最终可能产生两种结果:找到目标结点,或扩展完所有结点而没有找到目标结点。
对于广度优先搜索算法来说,问题不同则状态结点的结构和结点扩展规则是不同的,但搜索的策略是相同的。广度优先搜索算法的框架一般如下:
1 | void BFS() |
一些常用算法和数据结构
分治算法:
分治法在每一层递归上都有三个步骤:
step1 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
step2 解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
step3 合并:将各个子问题的解合并为原问题的解。
它的一般的算法设计模式如下:
Divide-and-Conquer(P) 1. if |P|≤n0 2. then return(ADHOC(P)) 3. 将P分解为较小的子问题 P1 ,P2 ,...,Pk 4. for i←1 to k 5. do yi ← Divide-and-Conquer(Pi) △ 递归解决Pi 6. T ← MERGE(y1,y2,...,yk) △ 合并子问题 7. return(T)其中|P|表示问题P的规模;n0为一阈值,表示当问题P的规模不超过n0时,问题已容易直接解出,不必再继续分解。ADHOC(P)是该分治法中的基本子算法,用于直接解小规模的问题P。因此,当P的规模不超过n0时直接用算法ADHOC(P)求解。算法MERGE(y1,y2,…,yk)是该分治法中的合并子算法,用于将P的子问题P1 ,P2 ,…,Pk的相应的解y1,y2,…,yk合并为P的解。
依据分治法设计程序时的思维过程
实际上就是类似于数学归纳法,找到解决本问题的求解方程公式,然后根据方程公式设计递归程序。
1、一定是先找到最小问题规模时的求解方法
2、然后考虑随着问题规模增大时的求解方法
3、找到求解的递归函数式后(各种规模或因子),设计递归程序即可。贪心算法(Greedy Algorithm) 简介
贪心算法,又名贪婪法,是寻找最优解问题的常用方法,这种方法模式一般将求解过程分成若干个步骤,但每个步骤都应用贪心原则,选取当前状态下最好/最优的选择(局部最有利的选择),并以此希望最后堆叠出的结果也是最好/最优的解,但贪心算法得到的结果不一定是最优的结果。{看着这个名字,贪心,贪婪这两字的内在含义最为关键。这就好像一个贪婪的人,他事事都想要眼前看到最好的那个,看不到长远的东西,也不为最终的结果和将来着想,贪图眼前局部的利益最大化,有点走一步看一步的感觉。}
贪婪法的基本步骤:
步骤1:从某个初始解出发;
步骤2:采用迭代的过程,当可以向目标前进一步时,就根据局部最优策略,得到一部分解,缩小问题规模;
步骤3:将所有解综合起来。最小生成树:
问题背景:给定7个村庄,现在要修路把7个村庄连通,各个村庄的距离用边线表示(也就是每条边的权),如何修路保证各个村庄都能连通,并且总的修建公路里程最短?
prim算法:将n个点连通最少需要n-1条边,从任意一个点开始,把这个点加入一个集合中,找到集合中的所有点能连通的其他点的所有路,选择距离最短(权最小)的一条路,然后把这条路的终点加入到集合中,重复次过程直到集合中有n个点
kruskal算法:先将所给的存在的能所有边按照权值从小到大的顺序进行排序放入一个集合中,依次从排序后的集合中取出一条边,判断这条边加入已修好路的集合中会不会产生回路,如果产生回路,则跳过这条边,从小到大的顺序选择下一条边,如果没有产生回路,则把这条边加入修路集合,直到修路集合中的边的条数为n-1
两种算法的区别是prim算法的修路集合中的点一定都是连通,因为是从已有的所有点中扩展出去的,但kruskal算法的修路集合中的点不一定都是连通的,因为是按照权值从小到大进行选择,两次选择的边可以没有相同顶点,所以不一定连通
单调栈
- 单调递增栈:从栈底到栈顶,栈中的值单调递增
- 单调递减栈:从栈底到栈顶,栈中的值单调递减
单调栈则主要用于解决NGE问题(Next Greater Element),也就是,对序列中每个元素,找到下一个比它大的元素。(当然,“下一个”可以换成“上一个”,“比它大”也可以换成“比他小”,原理不变。)
我们维护一个栈,表示“待确定NGE的元素”,然后遍历序列。当我们碰上一个新元素,我们知道,越靠近栈顶的元素离新元素位置越近。所以不断比较新元素与栈顶,如果新元素比栈顶大,则可断定新元素就是栈顶的NGE,于是弹出栈顶并继续比较。直到新元素不比栈顶大,再将新元素压入栈。显然,这样形成的栈是单调递减的。
单调队列
- 单调递增队列:保证队列头元素一定是当前队列的最小值,用于维护区间的最小值。
- 单调递减队列:保证队列头元素一定是当前队列的最大值,用于维护区间的最大值。
在说具体怎么实现一个单调队列之前,先来一个简单的例子,感受一下。
给定数列:
[3,1,5,7,4,2,1]现在要维护区间长度为 3 的最大值。(区间的下标从0开始)数列遍历到的位置 操作 队列中元素 指定区间最大值 0 3入队 3 区间大小不符合 1 1入队 3,1 区间大小不符合 2 3,1出队,5入队 5 区间[0,2]的最大值为5 3 5出队,7入队 7 区间[1,3]的最大值为7 4 4入队 7,4 区间[2,4]的最大值为7 5 2入队 7,4,2 区间[3,5]的最大值为7 6 1入队,7出队 4,2,1 区间[4,6]的最大值为4 可以发现队列中的元素都是单调递减的(不然也就不叫单调递减队列啦),同时既有入队列的操作、也有出队列的操作。
实现流程:
实现单调队列,主要分为三个部分:
去尾操作 :队尾元素出队列。当队列有新元素待入队,需要从队尾开始,删除影响队列单调性的元素,维护队列的单调性。(删除一个队尾元素后,就重新判断新的队尾元素)。去尾操作结束后,将该新元素入队列。
删头操作 :队头元素出队列。判断队头元素是否在待求解的区间之内,如果不在,就将其删除。(这个很好理解呀,因为单调队列的队头元素就是待求解区间的极值)
取解操作 :经过上面两个操作,取出 队列的头元素 ,就是 当前区间的极值 。
去尾操作:队尾元素出队列
假设需要维护一个 区间长度为 L 的 最大值,显然,我们需要一个 单调递减队列。
现在有一个新元素 new(下标为new_id)待放入队列,在新元素 new 入队列之前,需要先执行下面的操作:
- 如果当前 队列为空,则 直接将new放入队列 。否则,执行下一步。
- (假设队列的尾元素为rear)当前 队列不为空 。
- 如果rear<new,则 尾元素rear出队列,直到 当前队列为空 或者 rear<new不再满足。紧接着,元素new入队列。
- 如果rear>=new,直接将元素new放入队列。
删头操作:队头元素出队列
将新元素new入队列之后,我们还需要判断当前队列中 队头元素 是否在 待求解的区间范围 内。
假设队列的头元素为front(序号为front_id)。如果此时当前 队列不为空 ,且front_id<new_id-L+1,那么将队列头元素front出队列。不断重复此过程,直至front_id>=new_id-L+1(也就是将队列中序号不在区间[new_id-L+1,new_id]的元素删除)
取解操作
经过上面的操作,此时 队列的头元素就是区间[new_id-L+1,new_id] 的最大值。
动态规划
动态规划特点
「分治」是算法中的一种基本思想,其通过将原问题分解为子问题,不断递归地将子问题分解为更小的子问题,并通过组合子问题的解来得到原问题的解。类似于分治算法,「动态规划」也通过组合子问题的解得到原问题的解。不同的是,适合用动态规划解决的问题具有「重叠子问题」和「最优子结构」两大特性。
重叠子问题
动态规划的子问题是有重叠的,即各个子问题中包含重复的更小子问题。若使用暴力法穷举,求解这些相同子问题会产生大量的重复计算,效率低下。动态规划在第一次求解某子问题时,会将子问题的解保存;后续遇到重叠子问题时,则直接通过查表获取解,保证每个独立子问题只被计算一次,从而降低算法的时间复杂度。
最优子结构
如果一个问题的最优解可以由其子问题的最优解组合构成,并且这些子问题可以独立求解,那么称此问题具有最优子结构。动态规划从基础问题的解开始,不断迭代组合、选择子问题的最优解,最终得到原问题最优解。
并查集
- 定义:
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题(即所谓的并、查)
- 主要构成:
并查集主要由一个整型数组pre[ ]和两个函数find( )、join( )构成。
数组 pre[ ] 记录了每个点的前驱节点是谁,函数 find(x) 用于查找指定节点 x 属于哪个集合,函数 join(x,y) 用于合并两个节点 x 和 y 。- find( )函数的定义与实现:
首先我们需要定义一个数组:int pre[1000]; (数组长度依题意而定)。这个数组记录了每个人的上级是谁。这些人从0或1开始编号(依题意而定)。比如说pre[16]=6就表示16号的上级是6号。如果一个人的上级就是他自己,那说明他就是教主了,查找到此结束。也有孤家寡人自成一派的,比如欧阳锋,那么他的上级就是他自己。
1
2
3
4
5
6int find(int x) //查找x的教主
{
while(pre[x] != x) //如果x的上级不是自己(则说明找到的人不是教主)
x = pre[x]; //x继续找他的上级,直到找到教主为止
return x; //教主驾到~~~
}- join( )函数的定义与实现
join(x,y)的执行逻辑如下:
1、寻找 x 的代表元(即教主);
2、寻找 y 的代表元(即教主);
3、如果 x 和 y 不相等,则随便选一个人作为另一个人的上级,如此一来就完成了 x 和 y 的合并。
下面给出这个函数的具体实现:1
2
3
4
5
6void join(int x,int y)
{
int fx=find(x), fy=find(y);
if(fx != fy)
pre[fx]=fy;
}- 路径压缩算法之一(优化find( )函数)
所谓路径压缩,就是将一个集合中所有元素的上级都设为代表元,这样查找效率很高,我们可以通过递归的方法来逐层修改返回时的某个节点的直接前驱(即pre[x]的值)。简单说来就是将x到根节点路径上的所有点的pre(上级)都设为根节点。
1
2
3
4
5
6
7
8
9int find(int x)
{
if(x == fa[x])
return x;
else{
fa[x] = find(fa[x]); //父节点设为根节点
return fa[x]; //返回父节点
}
}该算法存在一个缺陷:只有当查找了某个节点的代表元(教主)后,才能对该查找路径上的各节点进行路径压缩。换言之,第一次执行查找操作的时候是实现没有压缩效果的,只有在之后才有效。
- 路径压缩算法之二 加权标记法
点链接看看即可,有上面那个优化基本上可以解决大多数题目
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void union(int x,int y)
{
x=find(x);//寻找 x的代表元
y=find(y);//寻找 y的代表元
if(x==y) return ;//如果 x 和 y 的代表元一致,说明他们共属同一集合,则不需要合并,直接返回;否则,执行下面的逻辑
if(rank[x]>rank[y]){
pre[y]=x;//如果 x 的高度大于 y,则令 y 的上级为 x
}else if(rank[x]<rank[y]){//如果x的高度小于y,令x的上级为y
pre[x]=y;
}else{
rank[y]++; //如果 x 的高度和 y 的高度相同,则令 y 的高度加1
pre[x]=y; //让 x 的上级为 y
}
}